mpda 算法在 spark 下的使用及优越性
《MPDA:一种用于数据处理集群的大规模并行学习和依赖感知调度算法》由李青、陈星池等人撰写。文章提出了 MPDA 算法,通过快速训练机制和 GATNetwork,解决基于 DRL 调度算法训练慢和环境感知表示不足的问题,实验证明其在训练速度和调度性能上优势显著。
相关资源:
- 《MPDA: a Massively Parallel Learning and Dependency-Aware Scheduling Algorithm for Data Processing Clusters》
- DRL Sota 调度算法 Decima:https://github.com/hongzimao/decima-sim
- 基准数据集: https://www.tpc.org/tpch/
复现步骤:
我们的目标是论证论文中 MPDA 算法比 FIFO、SJF - CP 等启发式基线算法、基于 DRL 的 Decima 算法性能更好,按照以下步骤一步一步拆解每一步需要做的事情。
- 在本地环境中使用 docker 搭建所需的 spark cpu 环境
- 使用https://www.tpc.org/tpch/ 提供的数据集,跑一下 Decima 算法,获取执行任务所需的 JCT 时间
- 基于论文描述开发 MPDA 算法代码,在本地环境中用同样的 tpc 数据跑一下,获取平均 JCT 时间
复现实验记录
1. 实验环境搭建
机器配置
- 火山引擎 ecs.r3il.2xlarge 8 vCPU 64 GiB
使用 park project 模拟 spark sim
https://github.com/park-project/park/tree/master/park/envs/spark_sim
docker 搭建 spark cpu 环境
下面这份 docker-compose.yml 已经把你需要的四个组件——spark-master、spark-worker、spark-history 和 Jupyter Lab/Notebook——全部整合好,并且兼顾 Apple Silicon 与 x86 架构(镜像都提供 multi‑arch manifest,可自动匹配平台)。
yaml
version: '3.8'
services:
# 1️⃣ Spark Master
spark-master:
image: bitnami/spark:3.5 # 多架构镜像,可直接跑在 arm64 / amd64
container_name: spark-master
environment:
- SPARK_MODE=master
- ALLOW_EMPTY_PASSWORD=yes # 免密,本地开发即可;生产请改为账号密码
ports:
- '7077:7077' # RPC
- '8080:8080' # Master Web UI
volumes:
# ① 日志
- ./logs/spark-runtime:/opt/bitnami/spark/logs
# ④ Structured Streaming checkpoints
- ./checkpoints:/tmp/checkpoints
# ⑤ 数据
- ./data:/data
# 2️⃣ Spark Worker (如需更多 worker,直接复制改名即可)
spark-worker-1:
image: bitnami/spark:3.5
container_name: spark-worker-1
depends_on:
- spark-master
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://spark-master:7077
- SPARK_WORKER_MEMORY=2G # 根据 Mac mini 内存自行调整
- SPARK_WORKER_CORES=2 # 分配 CPU 核数
- ALLOW_EMPTY_PASSWORD=yes
ports:
- '8081:8081' # Worker Web UI
volumes:
# ① 日志
- ./logs/spark-runtime:/opt/bitnami/spark/logs
# ④ Structured Streaming checkpoints
- ./checkpoints:/tmp/checkpoints
# ⑤ 数据
- ./data:/data
# 3️⃣ Spark History Server
spark-history:
image: apache/spark:3.5.0
container_name: spark-history
entrypoint: ['/opt/spark/bin/spark-class', 'org.apache.spark.deploy.history.HistoryServer']
environment:
- SPARK_HISTORY_OPTS=-Dspark.history.fs.logDirectory=/opt/spark-events
ports:
- '18080:18080'
volumes:
- ./logs/spark-events:/opt/spark-events
# 4️⃣ Jupyter Notebook / Lab(内置 PySpark & Spark 3.5)
jupyter:
image: jupyter/pyspark-notebook:spark-3.5.0 # 官方 multi‑arch,内含 Spark + Hadoop 客户端
container_name: jupyter
depends_on:
- spark-master
environment:
# 连接外部 Spark 集群的关键:把 master URL 写入提交参数
- PYSPARK_SUBMIT_ARGS=--master spark://spark-master:7077 pyspark-shell
- SPARK_MASTER=spark://spark-master:7077
# 去掉默认 token,纯本地开发方便;如需安全自行设置
- JUPYTER_TOKEN=
ports:
- '8888:8888' # Jupyter UI
volumes:
- ./notebooks:/home/jovyan/work # 本地目录映射,持久化笔记使用说明
启动 / 停止
bashdocker compose up -d # 启动全部服务 docker compose down # 关闭并清理容器访问入口
组件 URL Spark Master UI http://localhost:8080 Spark Worker UI http://localhost:8081 History Server http://localhost:18080 Jupyter Lab http://localhost:8888 (首次进入无需 token) 在 Jupyter 中使用 PySpark
直接新建一个 Python Kernel,执行:
pythonspark变量
spark已自动注入(由pyspark-notebook镜像完成),并连接到spark://spark-master:7077。提交脚本也可以在命令行用:
bashdocker exec -it spark-master spark-submit \ --master spark://spark-master:7077 /path/to/your_app.py
关键镜像多架构支持
- Bitnami Spark 3.5 最近已提供 arm64 与 amd64 镜像标签,Mac mini (M1/M2) 原生运行无须 Rosetta。([Docker Hub][1])
- jupyter/pyspark-notebook:spark-3.5.0 同样标注
linux/arm64/v8,可以直接在 Apple Silicon 拉取并运行。([Docker Hub][2])
⚠️ 如果你曾缓存过旧的 only‑amd64 标签,记得
docker pull --platform linux/arm64强制刷新。
这样一份 Compose 文件即可让你在 Mac mini 上“一键”启动完整的本地 Spark 学习/测试环境;后续需要扩容 worker、绑定自定义网络、增加端口或挂载数据卷,只需继续在同一个 docker-compose.yml 文件里改动即可。祝你玩得开心 🚀
2. MPDA 代码架构分析
1. 项目结构
SpeedScheduler 是一个基于深度强化学习(DRL)的 Spark 任务调度系统,主要由以下几个核心模块组成:
spark_env :Spark 模拟环境
- env.py :核心环境类,实现了 OpenAI Gym 接口
- job_dag.py :作业 DAG(有向无环图)的表示
- node.py :DAG 中的节点表示
- task.py :计算任务的表示
- job_generator.py :生成模拟作业
- reward_calculator.py :计算调度奖励
- tpch/ :包含 TPC-H 基准测试的数据集
attentional_decima :基于注意力机制的调度算法
- algorithm.py :实现了 AttentionalDecima 算法
utils :工具函数
- 数据缓冲区、消息传递、可视化等功能
主要执行文件 :
- start_master.py :启动主节点
- start_worker.py :启动工作节点
- actor.py :实现 Actor-Learner 架构中的 Actor
- learner.py :实现 Actor-Learner 架构中的 Learner
2. 核心功能
SpeedScheduler 实现了一个基于深度强化学习的 Spark 任务调度系统,主要功能包括:
- DAG 作业调度 :系统能够处理由多个计算阶段组成的 DAG 作业,决定何时调度哪个计算阶段以及分配多少执行器。
- 基于注意力机制的深度强化学习 :使用图神经网络和注意力机制处理不同规模的 DAG 作业,自动学习最优调度策略。
- 分布式训练架构 :采用参数服务器架构,支持多个 Actor 并行收集经验,一个中央 Learner 进行模型更新。
- 高保真度模拟环境 :基于 Park 项目修改的 Spark 模拟器,能够模拟真实 Spark 集群的行为。
3. 工作原理
环境模拟 :
- 系统模拟了 Spark 的执行环境,包括执行器、任务、作业 DAG 等组件
- 使用 TPC-H 查询作为工作负载,每个查询被表示为一个 DAG
调度决策 :
- 系统需要做两个关键决策:选择哪个节点进行调度,以及分配多少执行器
- 调度算法考虑了 DAG 结构、任务执行时间、资源可用性等因素
强化学习训练 :
- 使用 Actor-Critic 架构进行训练
- 奖励函数基于作业完成时间(最小化平均完成时间或总体完成时间)
- 使用图神经网络处理 DAG 结构信息
分布式训练 :
- 多个 Actor 并行收集经验
- 中央 Learner 聚合经验并更新模型
- 使用参数服务器架构同步模型参数
4. 本地运行方法
要在本地运行 SpeedScheduler,需要按照以下步骤操作:
环境准备 :
- Python 3.7
- 安装依赖: tensorflow==1.15, numpy==1.18, scipy==1.5, networkx==2.5, pyarrow==3.0, tensorboardX, crc32c, pyyaml, pyzmq, matplotlib
配置文件 :
- 修改 config.yaml 文件,设置主节点 IP 地址和端口
- 可以在 params.py 中调整其他参数,如执行器数量、学习率等
启动系统 :
- 首先启动至少一个工作节点: python start_worker.py -f config.yaml
- 然后启动主节点: python start_master.py -f config.yaml
训练过程 :
- 系统会自动开始训练,通过多个 Actor 并行收集经验
- 训练结果会保存在 results 目录下
- 可以通过 TensorBoard 查看训练进度
5. 项目特点
- 可扩展性 :系统设计为可插拔架构,可以轻松替换环境或算法组件。
- 并行训练 :通过参数服务器架构实现大规模并行训练,加速强化学习过程。
- 高效调度 :通过学习 DAG 结构和任务特性,实现比传统启发式方法更高效的调度策略。
- 实用性 :虽然是模拟环境,但系统设计考虑了真实 Spark 集群的特性,有潜力应用于实际生产环境。 SpeedScheduler 项目展示了如何将深度强化学习技术应用于分布式数据处理系统的调度问题,为解决大规模计算集群的资源分配问题提供了新的思路。
3. MPDA 代码复现
1. 环境准备
- 安装 Python 3.7
- 安装依赖: tensorflow==1.15, numpy==1.18, scipy==1.5, networkx==2.5, pyarrow==3.0, tensorboardX, crc32c, pyyaml, pyzmq, matplotlib
conda create -n mpda python=3.7
conda activate mpda
pip install tensorflow==1.15 numpy==1.18 scipy==1.5 networkx==2.5 pyarrow==3.0 tensorboardX crc32c pyyaml pyzmq matplotlib2. 运行代码
- 启动工作节点
python start_worker.py -f config.yaml
- 启动主节点
python start_master.py -f config.yaml
- 查看训练结果:
tensorboard --logdir=results
# 指定端口号
tensorboard --host 0.0.0.0 --port 6006 --logdir=results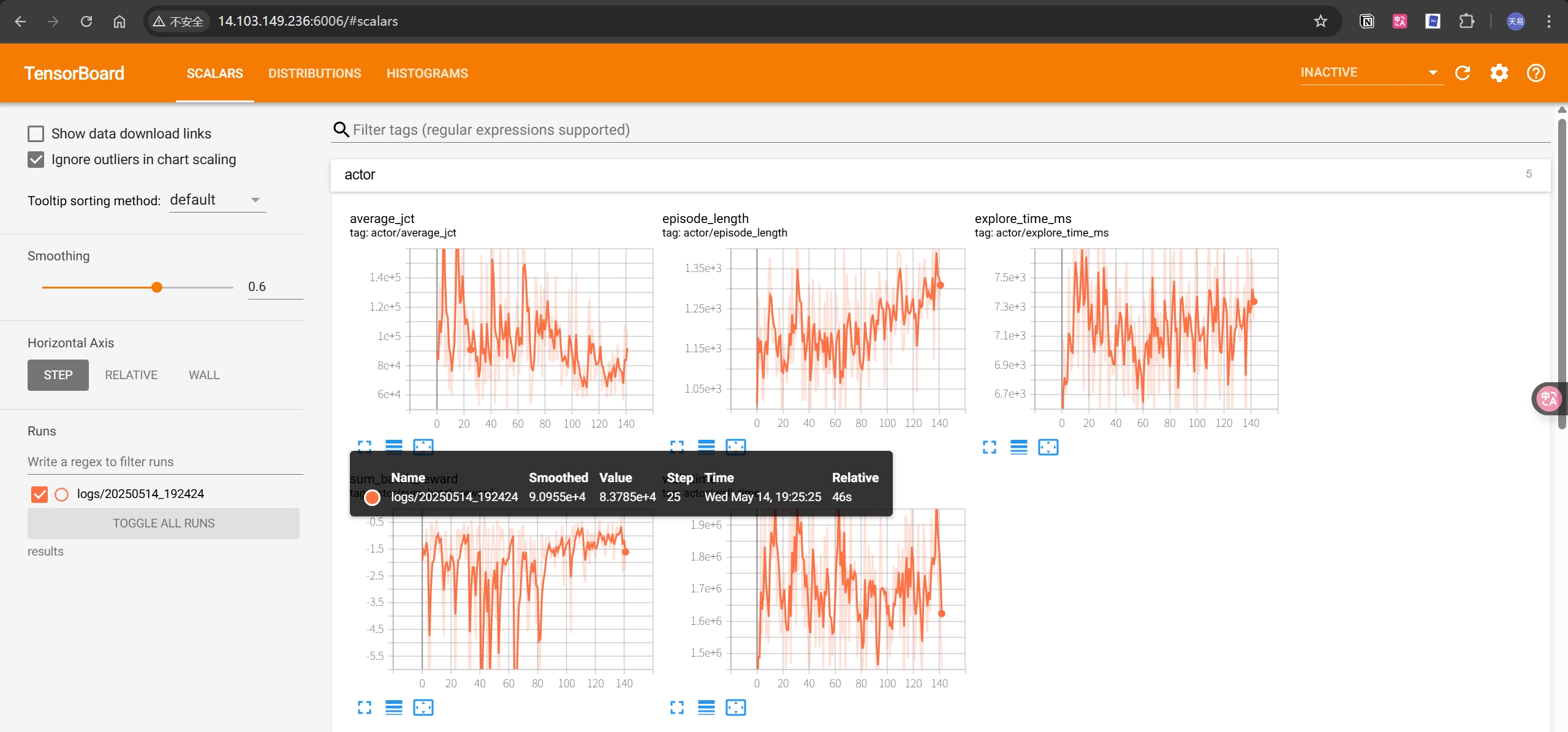
3. 结果分析
- 训练过程中,每个 Actor 会收集一定数量的经验,然后将经验发送给 Learner
- Learner 会聚合经验并更新模型
- 模型更新后,Actor 会重新收集经验
- 训练过程会持续进行,直到达到一定的迭代次数或达到一定的奖励阈值
- 训练结果会保存在 results 目录下,可以通过 TensorBoard 查看训练进度
4. decima 代码复现
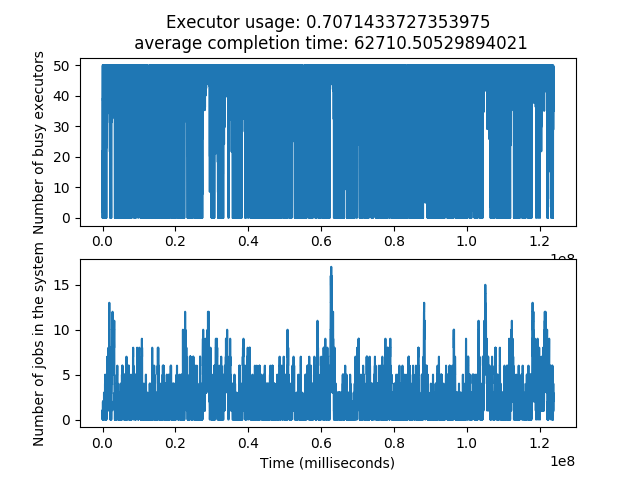
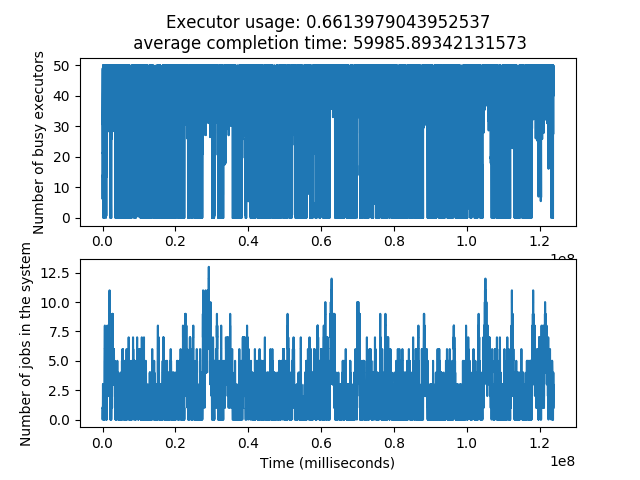
使用 50 个执行器,200 个流式作业,25 秒的泊松作业到达间隔(负载~85%),随机终止,输入相关的基线和平均奖励
python3 train.py --exec_cap 50 --num_init_dags 1 --num_stream_dags 200 --reset_prob 5e-7 --reset_prob_min 5e-8 --reset_prob_decay 4e-10 --diff_reward_enabled 1 --num_agents 16 --model_save_interval 100 --model_folder ./models/stream_200_job_diff_reward_reset_5e-7_5e-8/
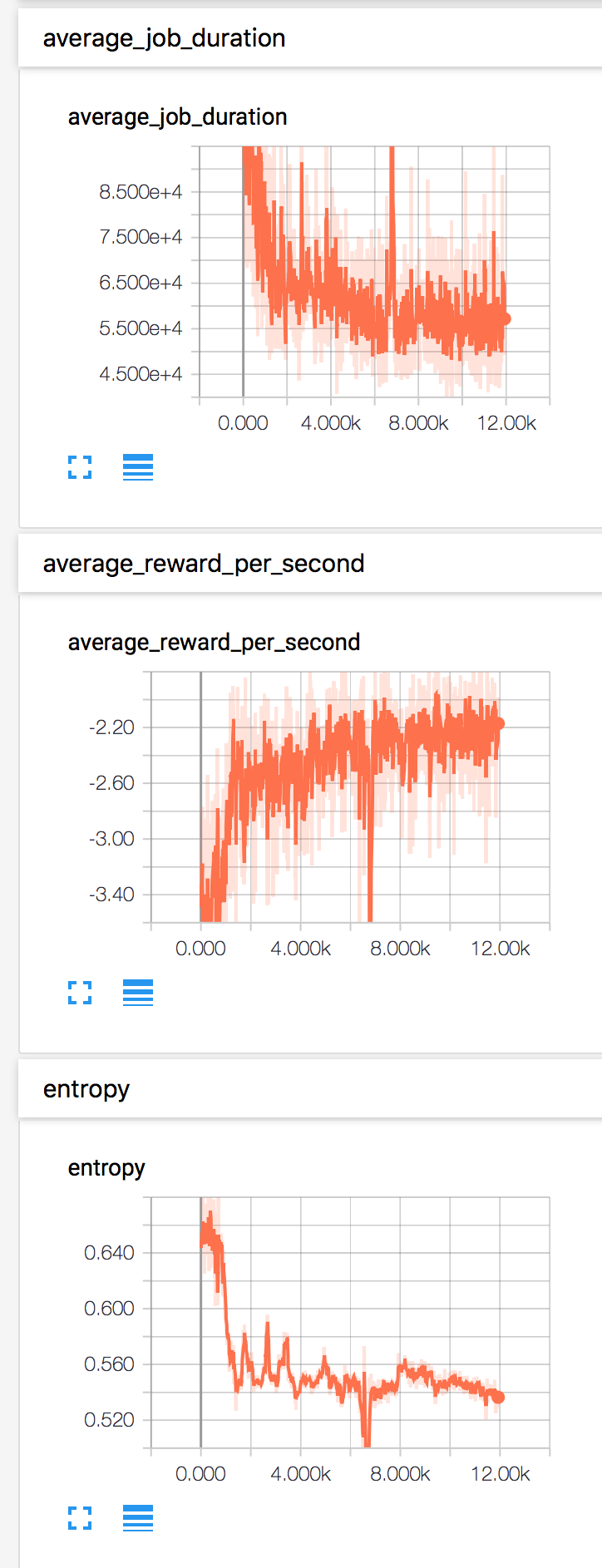
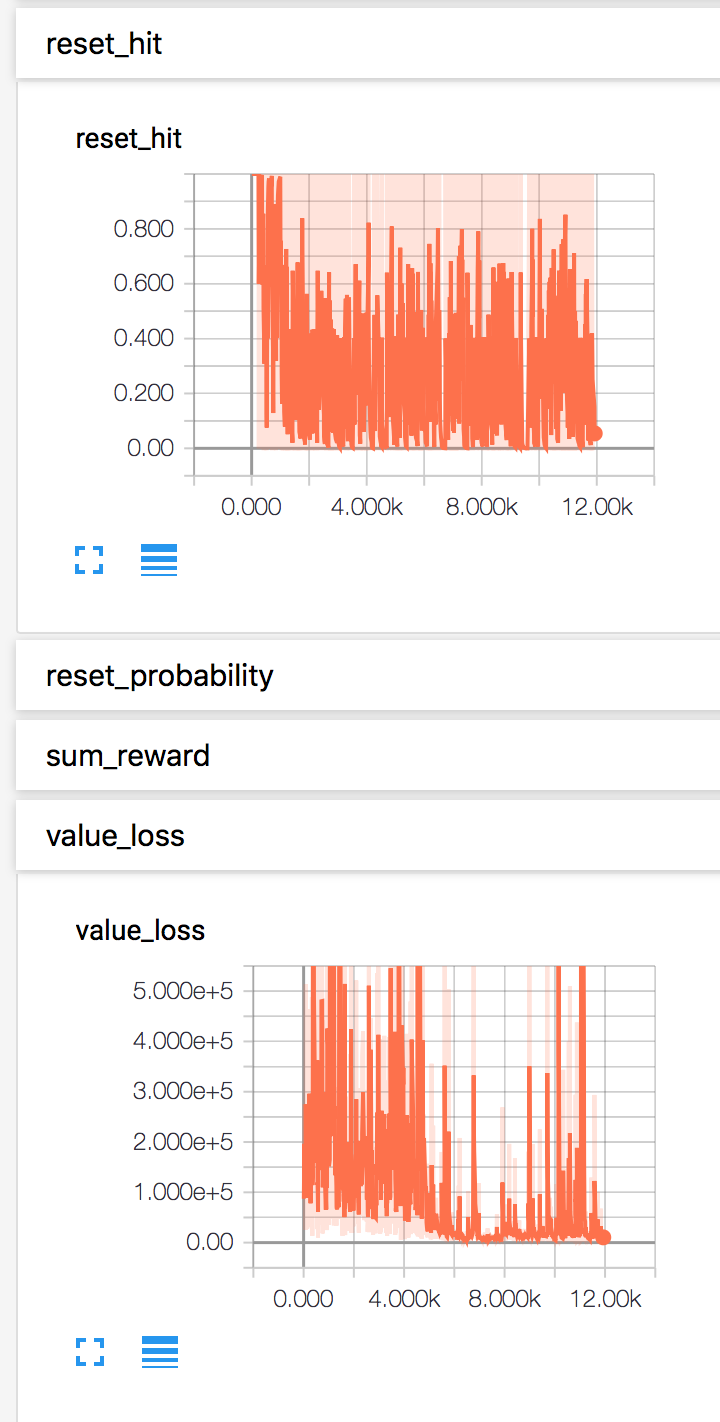
使用 tensorboard 监控训练过程,结果的一些截图